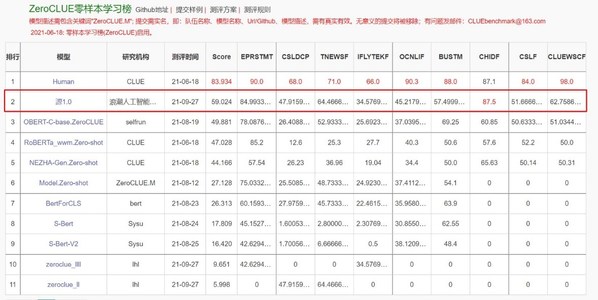
北京2022年1月5日 /美通社/ -- 近年來,BERT、GPT-3等大規(guī)模預訓練模型取得了巨大成功,引領語言模型進入巨量時代,算力、數(shù)據(jù)、參數(shù)規(guī)模快速朝著極致化的方向發(fā)展,也為模型訓練和部署帶來巨大挑戰(zhàn)。在近日舉行的2021 NeurIPS MeetUp China上,浪潮信息副總裁、AI&HPC產品線總經理劉軍基于2457億參數(shù)的“源1.0”中文語言模型,分享了浪潮人工智能研究院在巨量模型訓練與計算性能提升方面的領先實踐。
談及巨量模型訓練,劉軍表示:“訓練工作中最復雜也最具挑戰(zhàn)的技術點在于如何行之有效地完成數(shù)千萬級參數(shù)的模型訓練”。當前,GPU顯存最高為數(shù)十GB左右,而訓練‘源’這樣訓練數(shù)據(jù)集達5TB、參數(shù)量達2457億的大模型需要的GPU顯存高達幾TB,顯然無法在單個顯卡或一臺GPU服務器上完成。因此,巨量模型訓練工作,需要在模型算法、分布式訓練、大規(guī)模集群計算等各個層面進行協(xié)同設計、優(yōu)化,才能保證模型訓練過程收斂。
浪潮人工智能研究院需要將“源1.0”訓練所需的巨大算力并行分布到幾千張GPU上。模型訓練時最常采用的是數(shù)據(jù)并行分布式計算策略,但這只能滿足小模型的訓練需求。對于像“源 1.0”這樣的巨量模型而言,需要專門設計算法來解決訓練中的顯存占用問題,同時還要兼顧訓練過程中的GPU計算資源的利用率。
為此,浪潮采用了張量并行、流水線并行和數(shù)據(jù)并行的“三合一”并行策略。首先,將266臺AI服務器共計2128個GPU芯片分成7組,每組38臺AI服務器放置一個完整的“源1.0”大模型,其次,每組的38個服務器,采用流水并行每個服務器放置1/38的模型(2個Transformer Layer),一共76層;最后,在每臺服務器內采用張量并行,按照Transformer結構的每一層進行均勻切分。在此過程中,浪潮人工智能研究院也通過“增加序列長度”、“減少模型層數(shù)”、“增加隱藏層大小”、“增加節(jié)點中微批次大小”等模型結構策略,提升訓練效率。
Model |
Layers |
Hidden size |
Global BS |
Micro BS |
Sequence Length |
t |
p |
d |
GPUs |
Yuan 1.0 |
76 |
16384 |
3360 |
1 |
2048 |
8 |
38 |
7 |
2128 |
“源1.0”的模型結構以及分布式策略
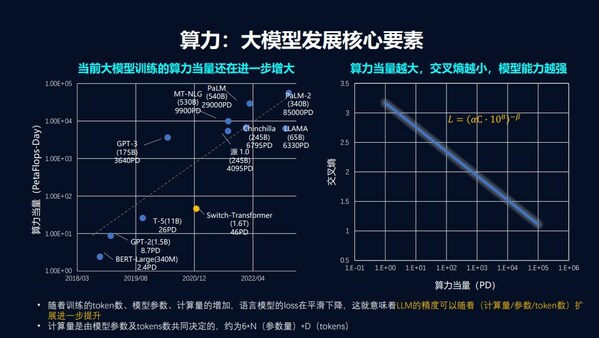
最終,浪潮人工智能研究院完成2457億參數(shù)的“源 1.0”模型訓練,總計訓練1800億個tokens,模型收斂的交叉熵為1.64。相較于GPT-3的1750億參數(shù),“源1.0”是其參數(shù)量的1.404倍。GPT-3使用10000塊GPU、花了30天訓練完成1750億參數(shù),“源1.0”在2128個GPU集群上跑了16天完成了訓練,使用更少GPU更快完成訓練,大幅提升計算效率。
“源1.0”消耗的總算力為4095 PetaFlop/s-day,每個GPU的實際訓練性能達到140 TFlops,GPT-3消耗的總算力為3640 PetaFlop/s-day,其單GPU計算性能為12 TFlops;而微軟和英偉達打造的5300億參數(shù)量的MT-NLG模型用了4480個A100 GPU,其單GPU計算性能為113 TFlops,也低于“源1.0”。

“源1.0”與 GPT-3 的參數(shù)量、算力對比。
浪潮人工智能研究院在實現(xiàn)更高計算效率的同時,也探索優(yōu)化大規(guī)模AI計算集群架構。當前,如MT-NLG等大規(guī)模深度學習模型需要在計算集群中采用8x200Gbps的IB互聯(lián)架構,而“源1.0”在集群架構設計上采用了2x200Gbps的高速網絡實現(xiàn)節(jié)點互聯(lián),“我們在實踐發(fā)現(xiàn),通過一定的優(yōu)化工作,可以使用更少網絡設備數(shù)量,取得更佳的計算性能。”劉軍表示。
巨量模型是當前人工智能研究的熱點,當前的巨量模型遠沒有達到模型能力的極限,增大模型參數(shù)量和訓練數(shù)據(jù)量仍然將帶來模型精度的持續(xù)提升。對于巨量模型的發(fā)展趨勢,劉軍表示,“巨量模型的計算量已經超過PetaFlop/s-day的階段,進入到ExtraFlop/s-day的階段。1 ExtraFlops等于1000 PetaFlops,因此可以說,GPT-3的計算量是3.64ExtraFlop/s-day,‘源1.0’的計算量則是4.095 ExtraFlop/s-day。從十年的尺度來看,今天我們還處于巨量模型起步階段,人類對計算的追求是沒有極限的,目前巨量模型消耗的計算量可能僅僅是未來一臺電腦的計算量。”劉軍對巨量模型的未來發(fā)展充滿信心。